42. ch06. sklearn - 앙상블 - 02. 보팅(Voting) 앙상블 -
45. ch06. sklearn - 앙상블 - 05. 부스팅(Boosting) 앙상블
42. ch06. sklearn - 앙상블 - 02. 보팅(Voting) 앙상블
Voting은 단어 뜻 그대로 투표를 통해 결정하는 방식
from sklearn.ensemble import VotingRegressor, VotingClassifier
Tuple 형태로 모델을 정의
single_models = [
('linear_reg', linear_reg),
('ridge', ridge),
('lasso', lasso),
('elasticnet_pipeline', elasticnet_pipeline),
('poly_pipeline', poly_pipeline)
]
voting_regressor = VotingRegressor(single_models, n_jobs=-1)
voting_regressor.fit(x_train, y_train)
voting_pred = voting_regressor.predict(x_test)
mse_eval('Voting Ensemble', voting_pred, y_test)
43. ch06. sklearn - 앙상블 - 03. 배깅(Bagging) 앙상블
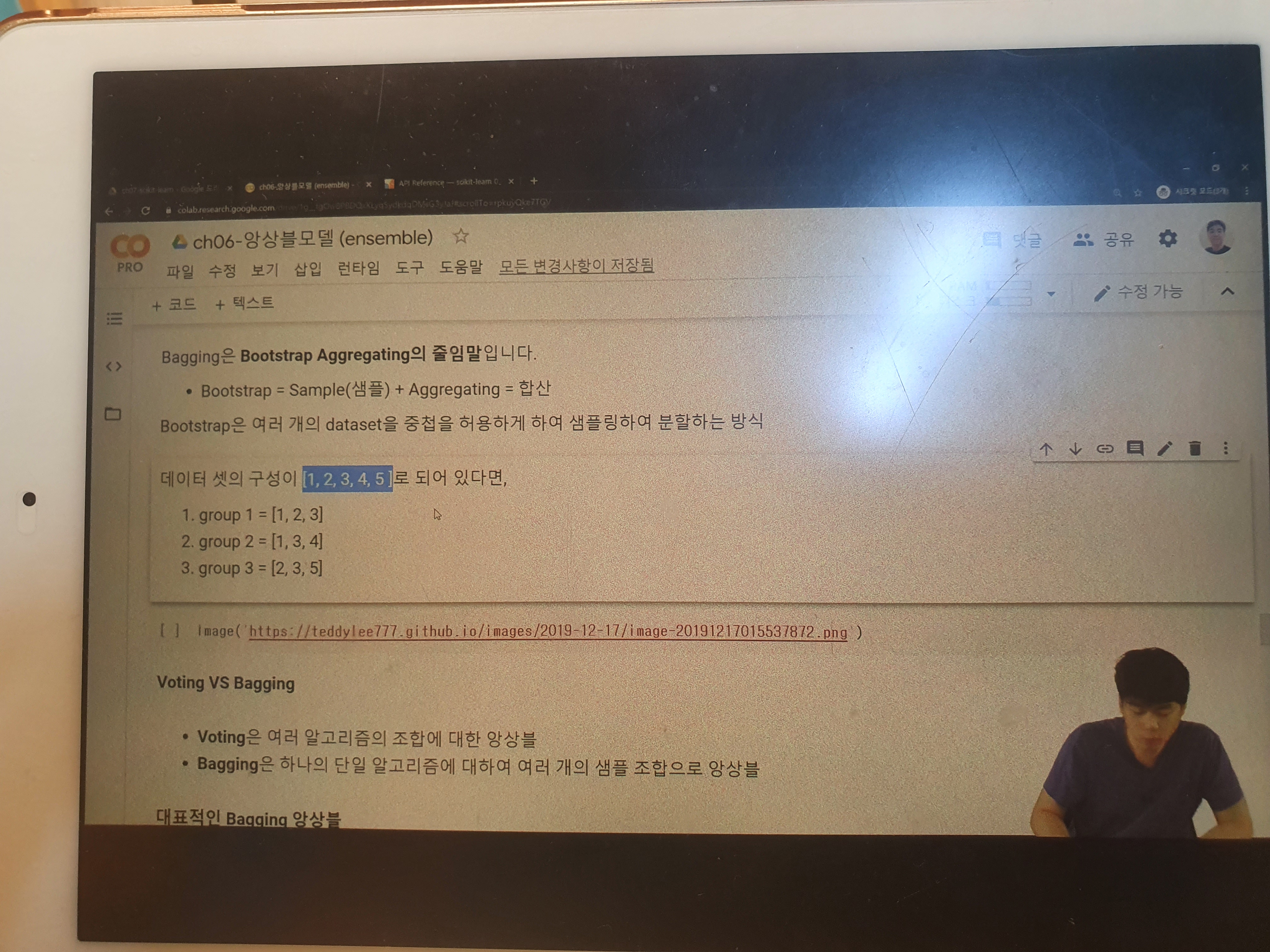
Bagging은 Bootstrap Aggregating의 줄임말입니다.
Bootstrap = Sample(샘플) + Aggregating = 합산
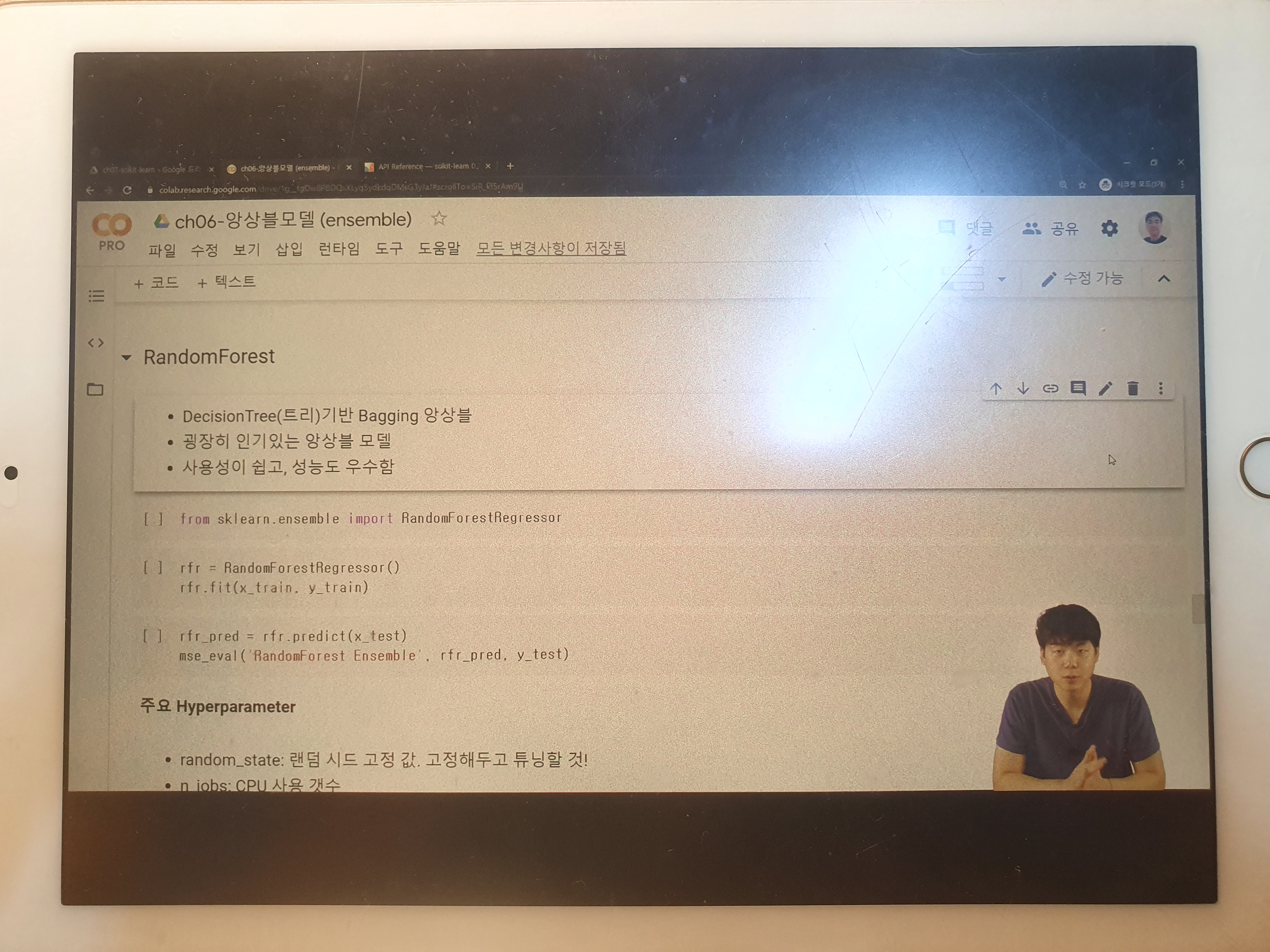
44. ch06. sklearn - 앙상블 - 04. 랜덤포레스트(RandomForest)
RandomForest
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
rfr = RandomForestRegressor()
rfr.fit(x_train, y_train)
rfr_pred = rfr.predict(x_test)
mse_eval('RandomForest Ensemble', rfr_pred, y_test)
튜닝을 할 땐 반드시 random_state 값을 고정시킵니다!
rfr = RandomForestRegressor(random_state=42, n_estimators=1000, max_depth=7, max_features=0.8)
rfr.fit(x_train, y_train)
rfr_pred = rfr.predict(x_test)
mse_eval('RandomForest Ensemble w/ Tuning', rfr_pred, y_test)
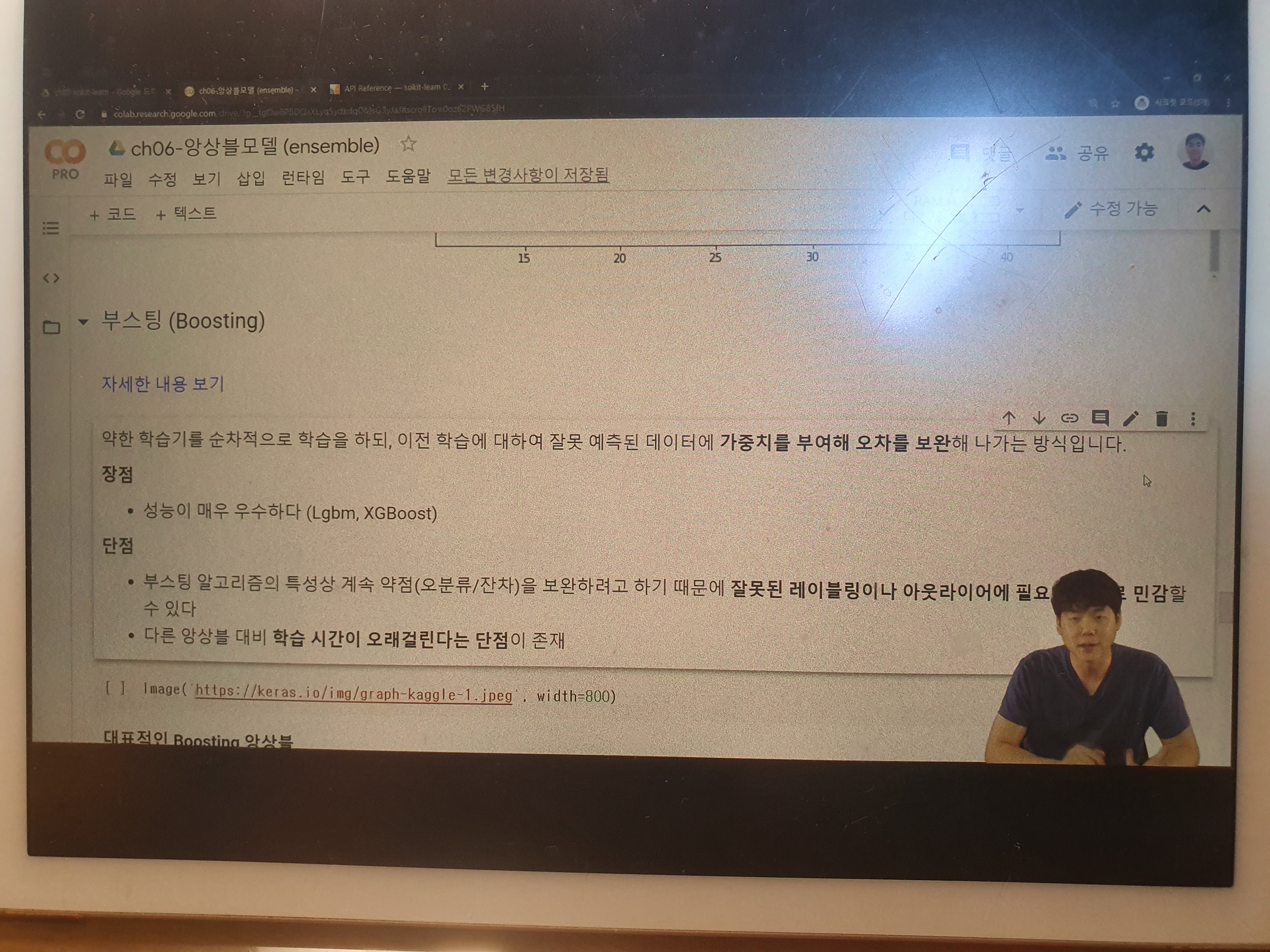
45. ch06. sklearn - 앙상블 - 05. 부스팅(Boosting) 앙상블
약한 학습기를 순차적으로 학습을 하되, 이전 학습에 대하여 잘못 예측된 데이터에 가중치를 부여해 오차를 보완
패스트캠퍼스 데이터분석 강의 링크
bit.ly/3imy2uN