[패스트캠퍼스 수강 후기] 데이터분석 인강 100% 환급 챌린지 43회차 미션
04. ch 01. EDA & 회귀 분석 - 03. 지도 학습과 회귀 분석 - 05. ch 01. EDA & 회귀 분석 - 04. Linear Regression을 이용한 수치
04. ch 01. EDA & 회귀 분석 - 03. 지도 학습과 회귀 분석
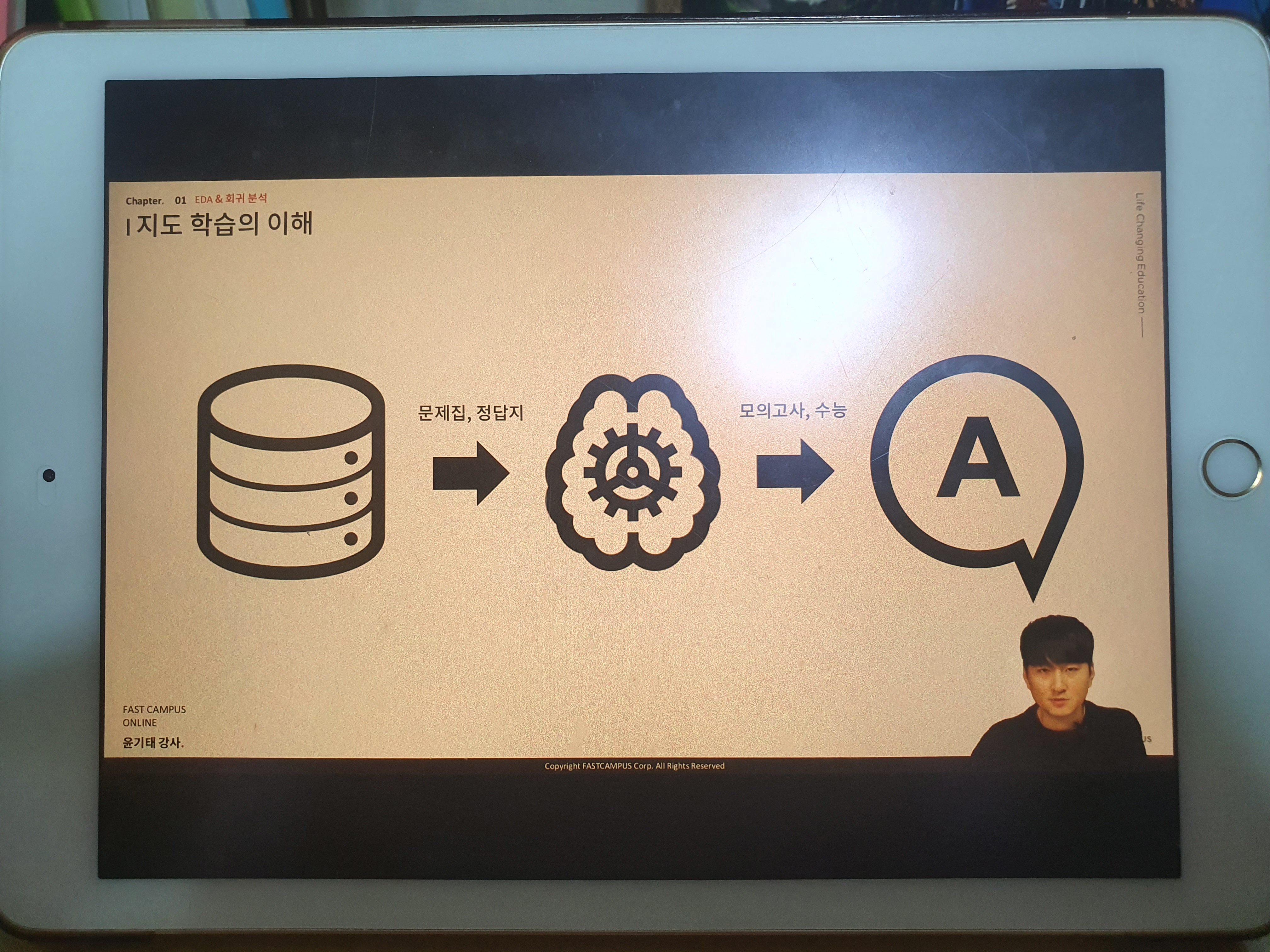
회귀 분석
설명 변수와 종속 변수간의 인과관계를 찾아내는 것
함수를 데이터에 맞추는 과정 (모델 학습 과정)
OLS (Ordinary Least Square)
vs MLE
모델 학습 과정 OLS (Ordinary Least Square)
제곱(Square)을 가장 작은(Least) 상태로 추정하는 것.
=
오차들의 제곱을 최소화 하는 것
그래디언트 디센트(Grandient Descent) (고급모델)
학습을 반복할때마다 줄어드는 오차를 반영하여 m과 b를 조금씩 근사시키는 방법
모델 평가 방법
결정계수(R-squared) - 데이터의 점들을 얼마나 잘 설명하고 있는가
F통계량
T-test 두 집단간의 차이.
유의도 얼마나 믿을 수 있느냐.
w가 0인지 아닌지에 대한 검정
F 통계량
0.001보다 현저하게 낮다. 유의미
다중 공선성
변수간의 강한 상관관계가 발생한 경우
회귀분석은 변수들간의 독립성이 보장되어야 함.
05. ch 01. EDA & 회귀 분석 - 04. Linear Regression을 이용한 수치
3-1) 데이터 전처리
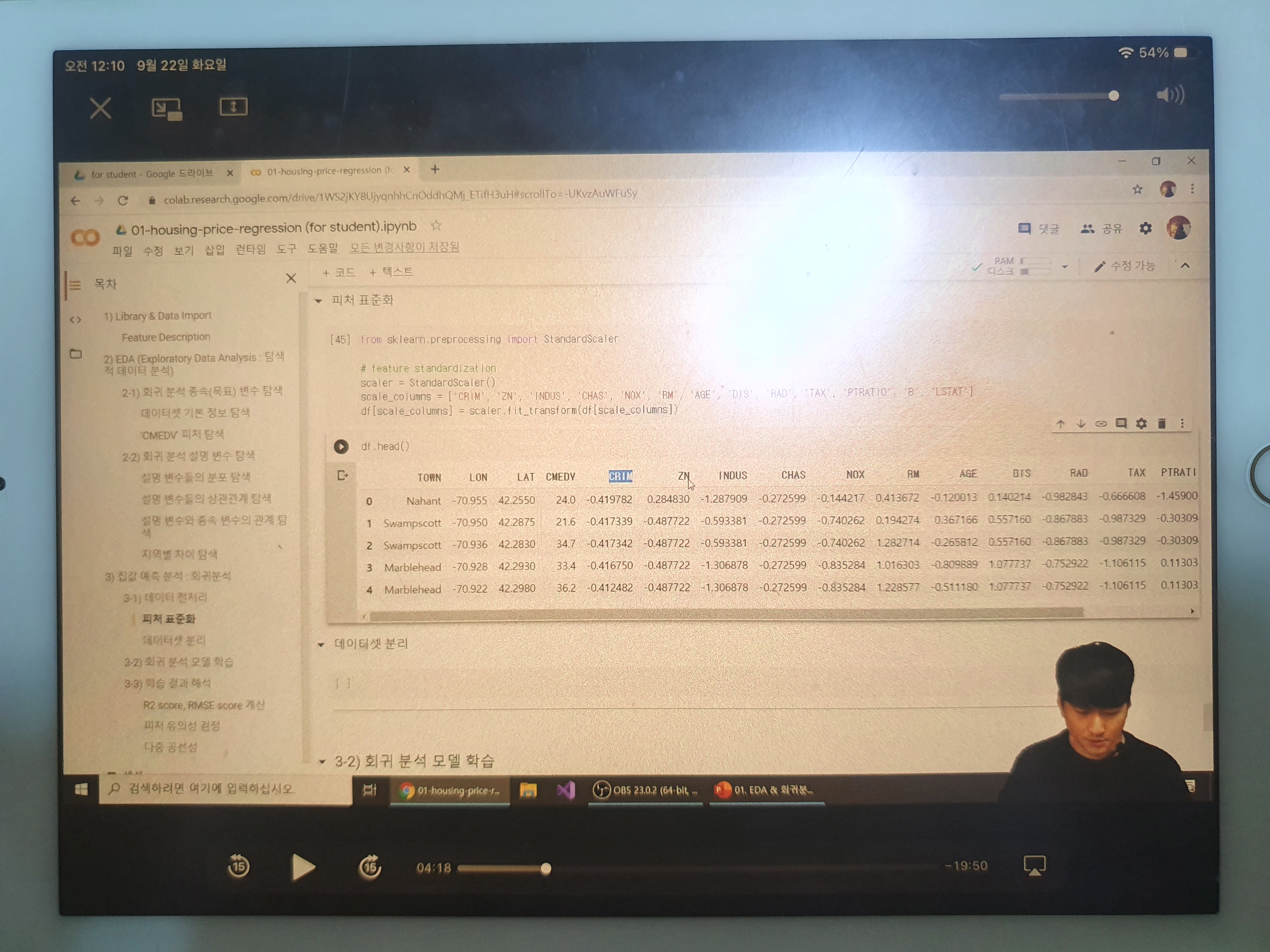
피처 표준화
피쳐간 단위를 맞춰줘야함.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scale_columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
df[scale_columns] = scaler.fit_transform(df[scale_columns])
df.head()
데이터셋 분리
from sklearn.model_selection import train_test_split
x = df[scale_columns]
y = df['CMEDV']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=33)
x_train 학습 문제집 학습만.
x_test 테스트 수능, 모의고사 추론만을 위한 것. 평가만
random_state 시드 번호를 주는 것. 결과 같게 나오기 위해
x_train.shape
3-2) 회귀 분석 모델 학습
from sklearn import linear_model
from sklearn.metrics import mean_squared_error
from math import sqrt
lr = linear_model.LinearRegression()
model = lr.fit(x_train, y_train) 문제집, 정답 넣어준 것.
print(lr.coef_) w, b가 궁금할 때 확인
plt.rcParams['figure.figsize'] = [12, 16]
coefs = lr.coef_.tolist()
coefs_series = pd.Series(coefs)
x_labels=scale_columns
ax = coefs_series.plot.barh()
ax.set_title('feature coef graph')
ax.set_xlabel('coef')
ax.set_ylabel('x_features')
ax.set_yticklabels(x_labels)
plt.show()
그래프
3-3) 학습 결과 해석
R2 score, RMSE score 계산
print(model.score(x_train, y_train))
75점 정도가 나왔다.
print(model.score(x_test, y_test))
실제 수능은 70점
피처 유의성 검정
y_predictions = lr.predict(x_train)
print(sqrt(mean_squared_error(y_train, y_predictions)))
루트. 문제집을 풀었을 때 학생이 낸 결과와 실제 결과
y_predictions = lr.predict(x_test)
print(sqrt(mean_squared_error(y_test, y_predictions)))
피처 유의성 검정
import statsmodels.api as sm
x_train = sm.add_constant(x_train)
model = sm.OLS(y_train, x_train).fit()
model.summary()
다중 공선성
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(x_train.values, 1) for i in range(x_train.shape[1])]
vif.head()
vif["feature"] = x_train.columns
vif.round(1)
패스트캠퍼스 데이터분석 강의 링크
bit.ly/3imy2uN